Hi,
I had been reading about this article on community. There is a paragraph that says
I am looking to understand the reasoning behind this, how it contributes to performance improvement if this order is followed.
Regards,
Aakash Sachdeva
@aakash
if those two modules are referencing each other and no other modules are referencing them or they are not referencing other modules, then the order is correct. But, if any other modules are referencing these modules OR these modules are referencing other modules, then the order might need to be adjusted. Typically, you will use lists more frequently (in modules) than subsets and/or LISS (line item subsets), so a good rule of thumb would be to have the lists first, then subsets, and then LISS.
Remember, Anaplan is based on the DAG (Directed Acyclic Graph) meaning only line items are updated when needed or put another way, only the line items impacted are updated (not all of them). With that said, the article is attempting to get you to think of the entire calculation process of a cell update, the journey of the calculation from one module to the next, and how that entire calculation chain can perform at its peak.
You are looking at this in a very singular way (one or two modules) when you really need to be looking at the entire model.
Does that help?
Rob
I think that when a query is executed, Anaplan must scan all of the cube's dimensions to find the needed data. The order in which the dimensions are scanned can significantly impact the query's performance. If the dimensions are not in a logical order, it can be difficult for users to find the data that they need. This can make the cube less user-friendly.
Take a look at this article, hopefully it helps:
@rishi8118
your statement "If the dimensions are not in the correct order, Anaplan may not be able to find all of the data that is needed for the query. This can lead to inaccurate results." is incorrect. Dimensional order has nothing to do with the accuracy of the data, it affects the performance of the model.
Sorry, I didn't click on the hyperlink you linked. When you create a module, it uses the order in which the lists are defined in the General Lists:
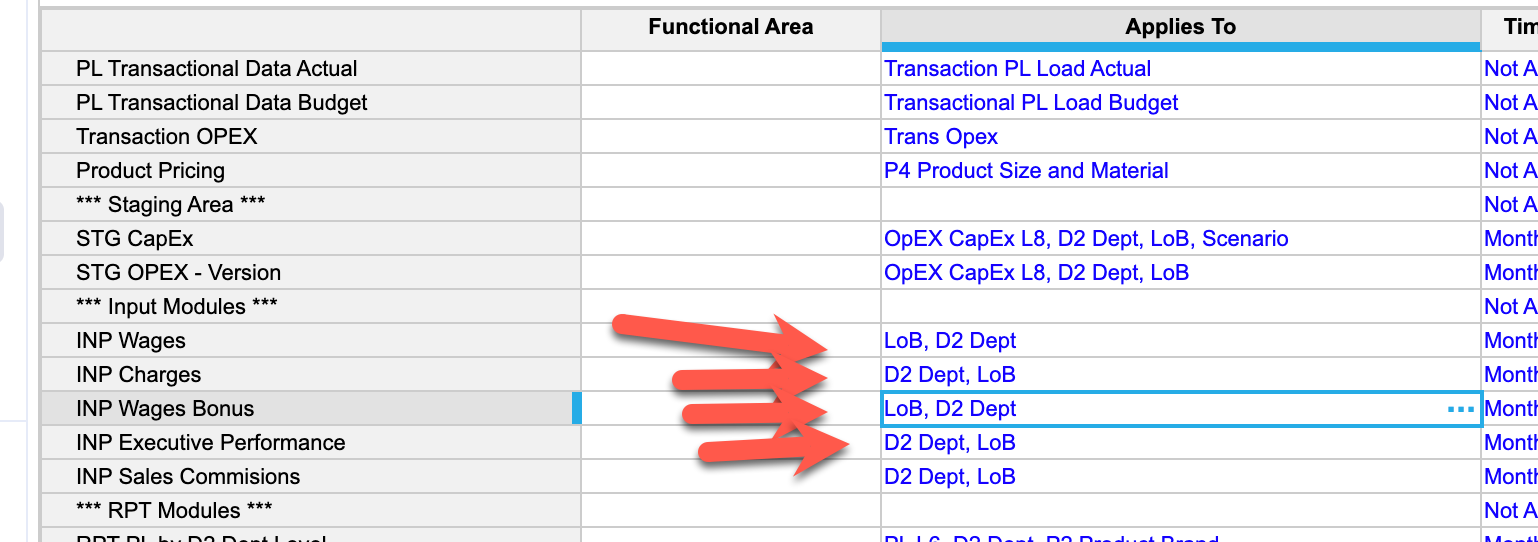
Meaning if I had a module dimensionalized by Planual and P3 Model, it will place P3 Model first and then Planual.
Put simply, for best model performance, it is best to have modules using the same lists in the same order as it will help decrease the "read" time as the data is already in the same order.
Hi @rob_marshall,
Thank you for your answer, but I think I didn't make my point clear. I understand that when line items formulas have multiple line items referred from multiple modules, keeping the modules in same order make it easier to index, that make it faster. Now my question is 'Anaplan says keep lists first, then subsets, and then line item subsets' , I want to understand how keeping subsets after lists contributes to performance and same for Line Item Subsets, I could have two modules where dimensions are in same order but Subsets occur before list.
Do let me know if need any more clarification.
Hi @rishi8118,
I do appreciate your response, though it's not what I am asking for, but can you please quote any reference for the below highlighted part in your answer which I believe is incorrect. If you agree with me, kindly remove that part so that it does not lead to any confusion for other users.
"Anaplan says keep lists first, then subsets, and then line item subsets' , I want to understand how keeping subsets after lists contributes to performance and same for Line Item Subsets, I could have two modules where dimensions are in same order but Subsets occur before list." That is order they are listed when creating a new module and you can't change that.
What that document is really talking about is at the module level, and really at the line item level when using subsidiary views.
The below would be a "bad" way of defining the module and the lists.
A better, more performant way is to have these lists for these modules in the same order: D2 Dept, LoB Flat
Can you please help me understand if the below module sequences are incorrect or are not as per best practices?
LIS - Test 1 is a Line Item Subset
List Subset : Test Subset is a list subset
M1 List of Modules is a list
Does that article wants me to keep the order as 'M1 List of Modules', 'List Subset', 'LIS - Test 1' in both the modules? If yes, then what's the impact of that?
Hi @rob_marshall ,
Yes, thanks a lot, that answers my question and I do think we should update that article as well to indicate what you just explained, the part which I highlighted where it asks to keep subsets after list seems to be a bit misleading. This would ensure people don't spend time on trying to optimize something that is not actually required.
Also, the below part from your answer got me really curious, are there any resources where I can study about such 'behind the scenes' elements? That would be really interesting
"Remember, Anaplan is based on the DAG (Directed Acyclic Graph) meaning only line items are updated when needed or put another way, only the line items impacted are updated (not all of them). With that said, the article is attempting to get you to think of the entire calculation process of a cell update, the journey of the calculation from one module to the next, and how that entire calculation chain can perform at its peak."
Thanks and Regards,
Hello everyone, I hope you're doing well. I'm posting because two of my coworkers are trying to use the Anaplan Excel Add-In Series 4, but they're running into an issue during the connection setup process. When they go to New → New Read-Only Connection (or New Connection) and reach the "Select a Customer" step, no…
Why in my model output is blank, after send explainability data.
I am working on a use case where I need to display the top 5 lines of a module as individual lines, while grouping all remaining lines under an "Others" category. The module is dimensioned by multiple composite hierarchy lists, along with Time and Version. To achieve this, I need to use the RANK function with the Ranking…