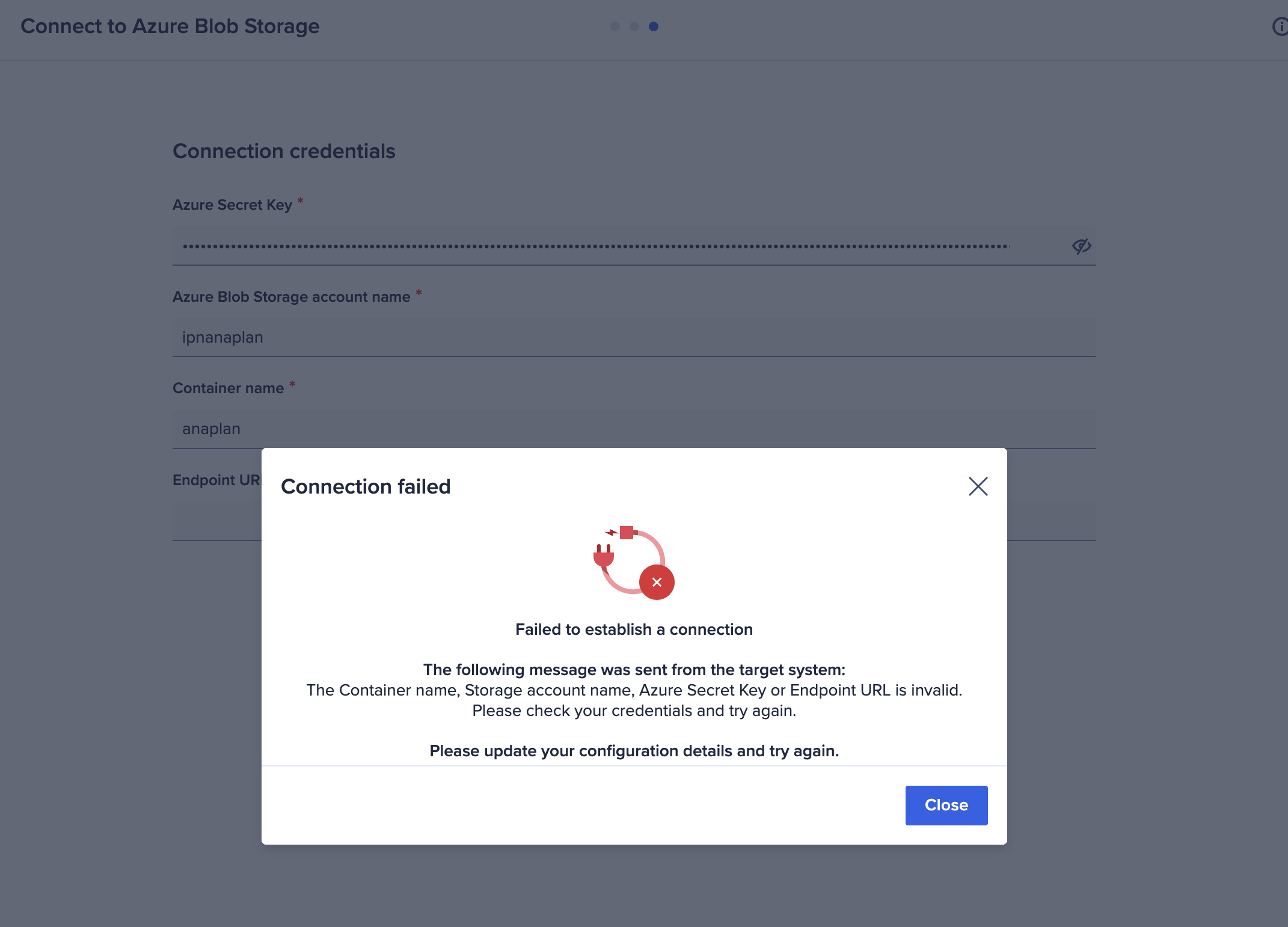
I am trying to connect to Azure blob, the credentials work on cloudworks, but do not work on ADO. Has anyone else experienced this issue?
Hello @jstockwell ,
In Cloudworks, the Azure Blob connection utilizes a SAS token for credentials, where as in ADO, Azure Blob uses an Azure Secret Key which cannot be the SAS token. Are you able to test creating a secret key with the proper permissions to access the Azure Blob container and test your connection in ADO? For reference on the ADO Azure Blob connection: https://help.anaplan.com/import-data-from-azure-blob-storage-c1c54d4d-c645-4ffe-98e6-ee8675b1894a Future State: ADO Azure Blob connection will be enhanced with the ability to use OAuth2.0 for connection into Azure Blob.
@JonFerneau,
We have a client that can only connect to Azure Blob using either Secure Access via RBAC AuthN+Z or Secured Network Access via Secure Tunnel / IP Whitelisting, per internal governance guidelines.
Are either of these options for establishing an ADO to Azure Blob connection, or will they need to seek another route to get their data into ADO?
@DavidEdwards , Currently, Azure Blob does not support secure tunnel connection. They can restrict access to their Azure Blob container to just Anaplan IP addresses, but I am not sure if this meets their requirements. Azure Blob also now supports OAuth within ADO so the use of SAS token is no longer required for connection.
We've been building a tool called aplan4sheets and we'd genuinely like input from this community — both on what we've built so far and on what we should prioritize next. The problem we set out to solve: Anaplan's Excel add-in is Windows-centric, and there's no real native way to pivot Anaplan data in Google Sheets. We…
A while back, I shared a pattern for extracting and reporting on Anaplan audit data using a Python project hosted on GitHub. I wrote that during my time on the Operational Excellence Group (OEG) at Anaplan. The Python solution still works, and plenty of teams are running it today. The problem it solves hasn't changed:…
We are looking for Anaplan end-users to provide feedback on their experiences with the Excel add-in. Interested individuals will respond to this 5-minute survey to help us understand personal needs and behavior when using the add-in. The feedback provided by survey takers is essential to the roadmap of Anaplan's products.…