
This article is part of a series on Polaris best practices. Click here for more Community content or visit Anapedia for detailed technical guidance.
This article explores how to optimize saved module views within the modeling experience, with particular attention to data import and export processes. We’ll revisit essential concepts from the classic Anaplan engine — now even more critical when working with Polaris, due to its ability to handle significantly larger datasets. Additionally, we’ll share new insights specific to the Polaris engine to help you make the most of its advanced capabilities.
Guidance for all views
Use a single Boolean filter
As discussed in Filter Best Practices (written for the classic engine in 2018!), the concept of using a single Boolean remains true — with some new guidance for Polaris: put all filter logic in a single Boolean. Placing all the filter logic into a single Boolean line item is more performant because Polaris evaluates the entirety of the logic at once, only doing the math where it needs to.
Old way:
Export? = A AND B
A = Line Item 1 <> 0
B = Line Item 2 <> 0
In this example of the “old way”, we are always calculating A and B as well as the “Export?” filter:

New way:
Export? = Line Item 1 <> 0 AND Line Item 2 <> 0
The Polaris engine reduces the math being done by looking at all conditions together, rather than individually, thus only evaluating the condition for Line Item 2 where the condition for Line Item 1 is true.
Even though the calc effort for “Export?” is slightly higher, we have eliminated the A and B filters completely and, as a result, reduced the total calc effort of this chain:

*Note: if the model requires the use of the conditionals for other calculations, or if the individual values need to be surfaced, it may still make sense to still have them broken out into separate line items.
Import-specific guidance
There are two sides to a model import when it comes to performance: pulling data from the source and loading that data into the target. When you encounter a slow model import action, it is important to distinguish between the two.
Optimizing import source views
First, optimize a source import using the guidance outlined above. The system takes extra time to handle and log any rejects or warnings, so it is also important to ensure that the import is clean.
Optimizing import target data loads
Import performance issues depend on whether data is being loaded into a list or a module. Updating a list alters the model’s structure, which triggers recalculations across dependent elements. To minimize impact, avoid letting users add list items or modify subsets in real time. Instead, schedule these changes during maintenance windows. If list updates are needed during planning cycles, consider creating extra list items in advance and hiding them with Boolean flags until they’re required.
To troubleshoot slow module imports in Polaris, allow the model to remain idle for 10 minutes*. Then, run the import actions and check the Calculation Effort column on the Line Items tab. Line items with non-zero values are being recalculated; prioritize optimizing those with the highest effort. For formula tuning guidance, see the optimization article linked below.
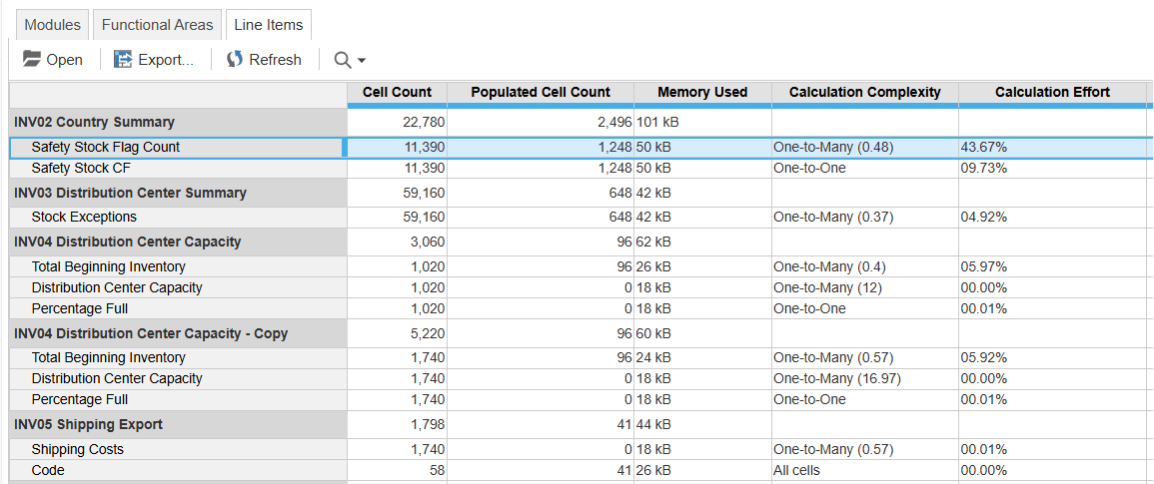
*Note this should be done in a version of the model which has sufficient data and list population to replicate the import performance needing optimization.
Avoid nested rows for import views
Using nested rows can be a useful way to filter a complex set of data, but the filter and thus view performance can be poor for large datasets. If you don’t need the rows nested for the purpose of filtering cell values, then you should not nest them. For example, in the screenshot below the store and time lists are nested to filter on values not equal to zero:
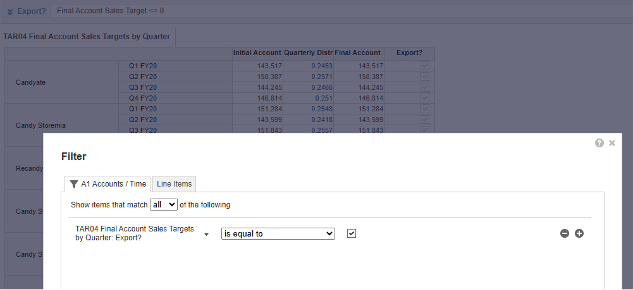
However, if we only need to filter on time, for example, nesting lists is unnecessary. As you can see below the import mapping layout is the same whether the time list is nested or not. By moving it to pages the view will be more performant.
Nested:
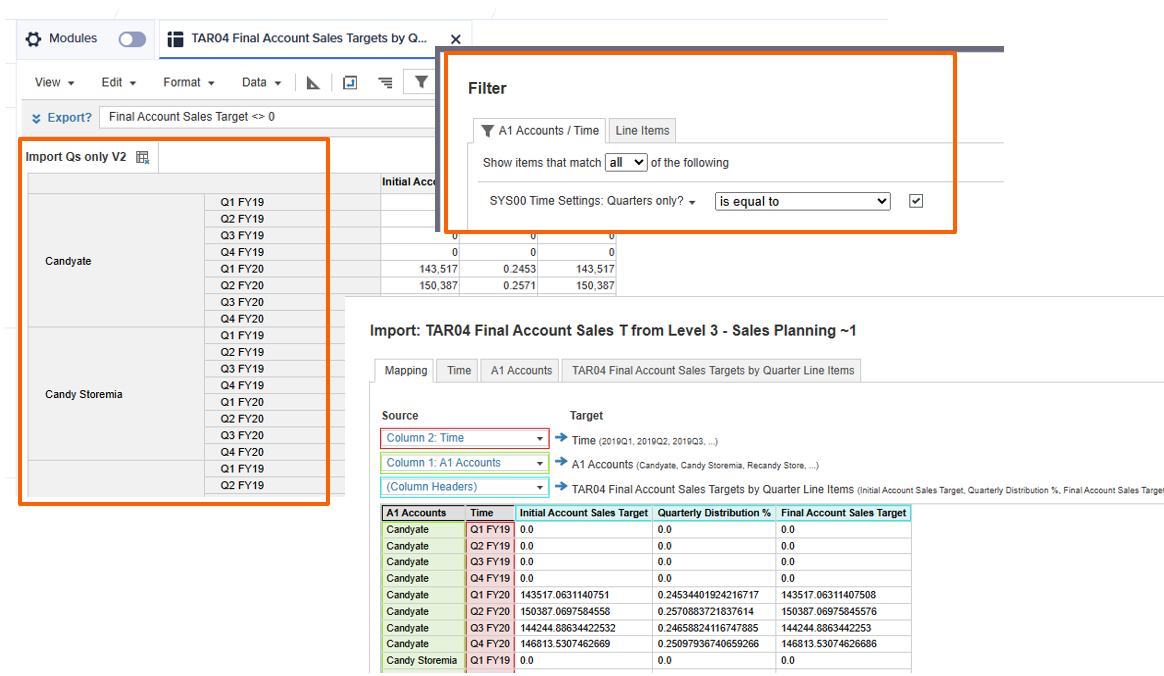
Not nested:
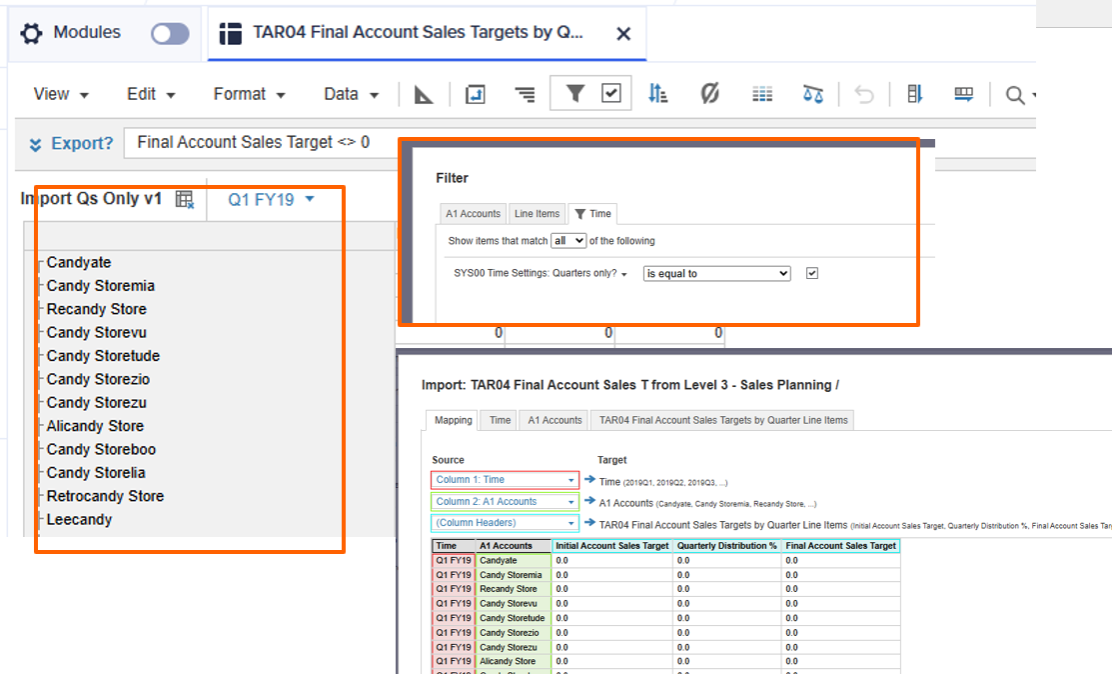
Export-specific guidance
Subsidiary views are not necessary for attributes in exports
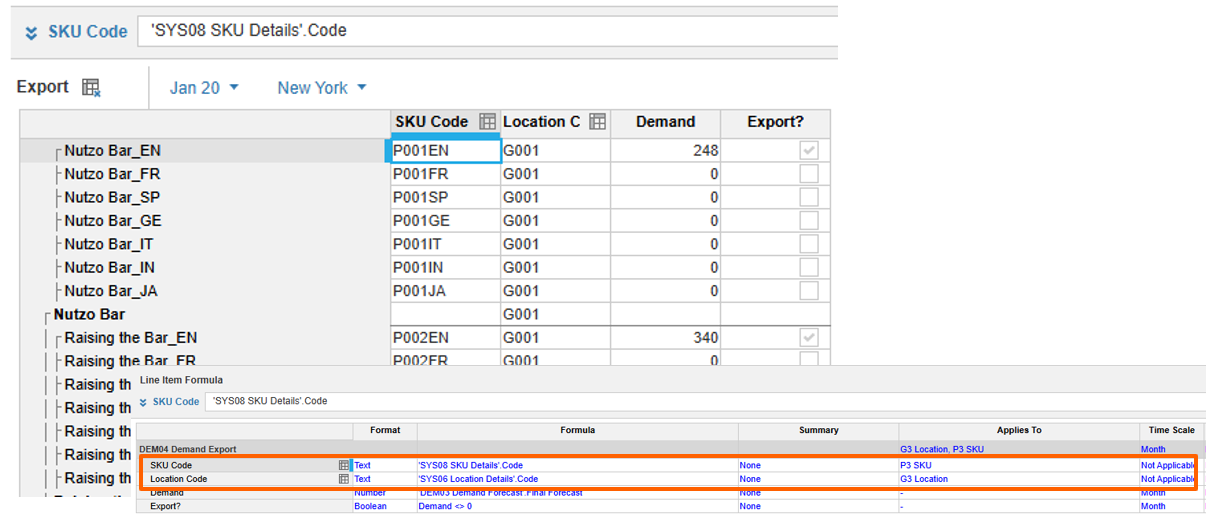
In the classic engine one of the known exceptions to the Planual rule “no subsidiary views” is when exporting attributes which don’t share dimensionality with the data being exported. Cutting out inapplicable dimensions avoids consuming memory for duplicated items, while allowing for the export of the necessary attributes. However, Polaris default values (0, blank, FALSE) use no memory, so attribute line items can match the export module's dimensionality. Defining attributes with full model dimensionality and using formulas to control population improves view performance and enables zero/blank suppression in exports and the UX.
Old way:
New way:
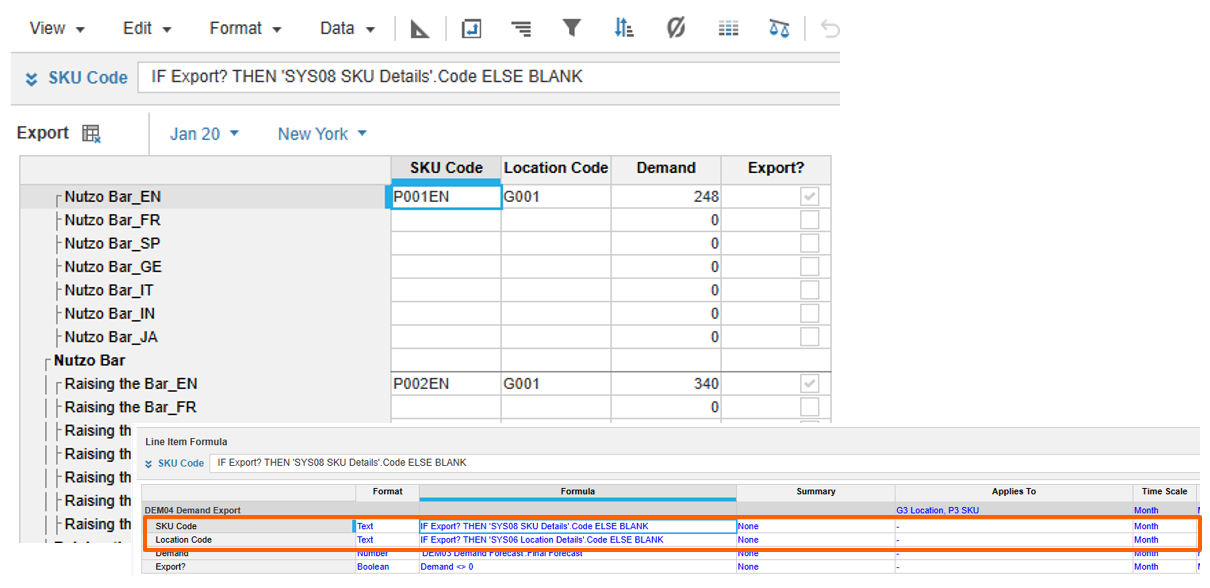
*This method may consume more memory, but the performance enhancement to actions and UX filtering is the tradeoff.
Avoid nested rows for export views
Using nested rows can be a useful way to filter a complex set of data for export, but the filter and thus view performance can be poor for large datasets. The best way around this is to pivot the dimensions so there is only one dimension in rows, and export using one of the column-based export options.
Line Items should be in columns, with no other lists
To facilitate the use of tabular multi-column export layout, as outlined below, you want line items pivoted to the column axis.
Use the Tabular Multiple Column export layouts
It’s important to note that the default “Grid” layout can be extremely performance heavy in both engines, but especially for the very large exports that can be created with Polaris. Not only does it require nested rows to export in a useable way, but for very large page dimensions it can churn for an extended period.
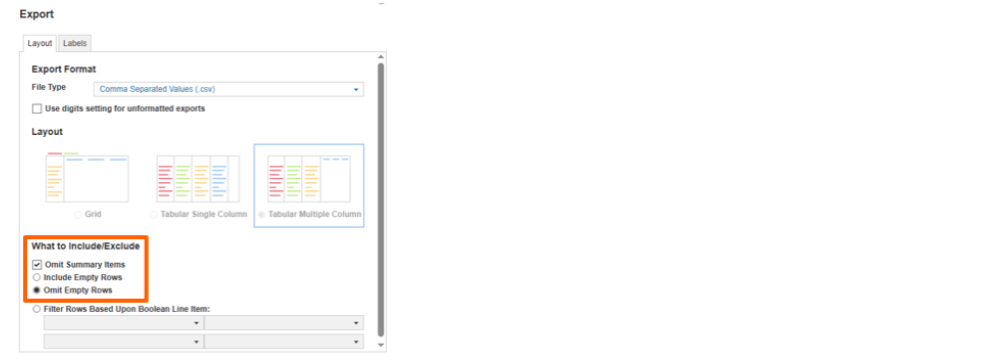
Using the Tabular Multiple Column layout option can improve performance, remove the need to nest dimensions in a view and allow for in-action boolean filtering. There are two setup options, depending on the requirements of the export:
- Using the “Omit Summary items” and the “Omit Empty Rows” options in addition to in-view Boolean filters.
- Using the “Omit Summary items” and the in-action boolean filters.
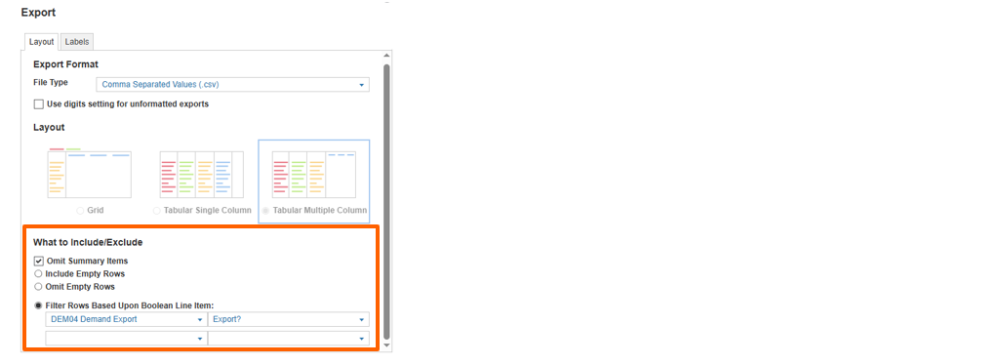
Note: The in-action filter offers faster performance and clear visibility into the applied filters. However, it exports all line items in the module, which can result in a larger file size. When deciding on your export method, consider the trade-offs between performance and file size.
If the structure of the module or view you're exporting from doesn't support the desired export format, consider redesigning the module to allow pivoting as needed. This may involve adjusting modules upstream of the export module to enable a more flexible structure. Additionally, if your export module serves multiple export formats, consider splitting it into separate modules based on specific front-to-back design use cases to improve clarity and maintainability.
To summarize
- Use a single boolean filter containing all filter logic.
- Avoid nesting dimensions if you can help it.
- Avoid using subsidiary views for large exports.
- Put line items in columns.
- Select tabular multi-column as your export format, utilizing the in-action filter when possible.
It’s important to remember that Polaris is capable of modelling to previously untapped levels of granularity and dimensionality. But with that power comes the responsibility to model intelligently and follow classic recommended best practices even more closely.
Article links:
Anaplan Polaris – Understanding Blueprint Insights and Optimizing for Populated Space
Creating More Flexible Export Definitions in Anaplan
……………..
Author: Anaplan’s Theresa Reid (@TheresaR).
Special thanks to Rob Marshall (@rob_marshall), Mark Warren (@MarkWarren), Adam Trainer (@AdamT), Mike Henderson (@hendersonmj), and Kai Lu (@KaiL) for their contributions.
